Ever felt overwhelmed by messy data scattered across systems? AWS Glue is your ultimate solution—a fully managed ETL service that simplifies data integration with zero infrastructure hassles. Let’s dive into how it transforms raw data into gold.

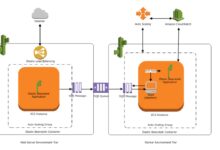
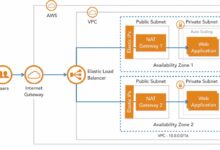

What Is AWS Glue and Why It Matters

AWS Glue is a fully managed extract, transform, and load (ETL) service provided by Amazon Web Services. It enables developers and data engineers to prepare and load data for analytics with minimal manual intervention. By automating much of the ETL process, AWS Glue reduces the time and effort required to move data between different sources and targets.
Core Definition and Purpose
AWS Glue is designed to streamline the data integration process. It automatically discovers, catalogs, transforms, and moves data across various data stores. Whether you’re dealing with structured, semi-structured, or unstructured data, AWS Glue provides a unified platform to manage it all.
- Automatically crawls data sources to infer schemas and generate metadata.
- Stores metadata in a central AWS Glue Data Catalog, accessible across AWS services.
- Generates Python or Scala code for ETL jobs, which can be customized as needed.
How AWS Glue Fits Into the AWS Ecosystem
AWS Glue integrates seamlessly with other AWS services such as Amazon S3, Amazon Redshift, Amazon RDS, Amazon DynamoDB, and Amazon Athena. This tight integration allows for end-to-end data workflows without the need for external tools or complex configurations.
- Works with Amazon S3 as a primary data lake storage.
- Feeds transformed data into Amazon Redshift for enterprise data warehousing.
- Supports querying via Amazon Athena using the Glue Data Catalog as a metadata repository.
“AWS Glue removes the heavy lifting from ETL, letting teams focus on insights rather than infrastructure.” — AWS Official Blog
Key Components of AWS Glue
To understand how AWS Glue operates, it’s essential to explore its core components. Each plays a critical role in automating and simplifying the ETL pipeline.
AWS Glue Data Catalog
The Data Catalog is a persistent metadata store that acts as a central repository for table definitions, schemas, and partition information. It’s compatible with Apache Hive metastore, making it easy to integrate with big data frameworks.
- Stores metadata from relational databases, JSON, CSV, Parquet, and more.
- Enables schema versioning and schema change tracking.
- Serves as the backbone for query engines like Athena and Redshift Spectrum.
Crawlers and Classifiers
Crawlers scan your data stores (like S3 buckets or JDBC sources) and automatically infer the schema. They use classifiers—predefined or custom—to identify data formats such as JSON, CSV, or Apache Avro.
- Run on a schedule or triggered manually.
- Update the Data Catalog with new tables or schema changes.
- Support custom classifiers using Grok patterns for log files or proprietary formats.
ETL Jobs and Scripts
ETL jobs are the heart of AWS Glue. These are executable units that transform and load data based on generated or user-defined scripts. AWS Glue uses Apache Spark under the hood, providing a serverless Spark environment.
- Scripts are auto-generated in Python (PySpark) or Scala.
- Jobs can be scheduled, monitored, and retried via AWS Console or CLI.
- Supports job bookmarks to track processed data and avoid reprocessing.
AWS Glue vs Traditional ETL Tools
Traditional ETL tools like Informatica, Talend, or IBM DataStage require significant setup, maintenance, and licensing costs. AWS Glue, being serverless and fully managed, offers a modern alternative with distinct advantages.
Serverless Architecture Advantage
With AWS Glue, there’s no need to provision or manage servers. The service automatically scales resources based on job complexity and data volume.
- No upfront infrastructure investment.
- Pay only for the compute time consumed during job execution.
- Automatic scaling eliminates performance bottlenecks.
Cost Efficiency and Operational Simplicity
Traditional ETL tools often come with high licensing fees and require dedicated administrators. AWS Glue operates on a pay-per-use model, making it cost-effective for both small and large-scale operations.
- Pricing is based on Data Processing Units (DPUs) used per minute.
- No idle resource costs—resources are allocated only during job runs.
- Reduced operational overhead due to automated monitoring and logging.
Integration with Modern Data Stacks
AWS Glue integrates natively with cloud-native services like S3, Lambda, CloudWatch, and Step Functions. This makes it ideal for modern data architectures such as data lakes and lakehouses.
- Triggers Glue jobs from Lambda functions based on S3 events.
- Uses Step Functions to orchestrate complex workflows involving multiple Glue jobs.
- Logs and monitors performance via Amazon CloudWatch.
Setting Up Your First AWS Glue Job
Creating your first AWS Glue job is straightforward. This section walks you through the step-by-step process using the AWS Management Console.
Step 1: Configure a Data Source with Crawlers
Start by setting up a crawler to scan your data source (e.g., an S3 bucket). The crawler will infer the schema and populate the Data Catalog.
- Navigate to the AWS Glue Console and select “Crawlers”.
- Create a new crawler, specify the data source (S3 path or JDBC connection).
- Choose a classifier (e.g., CSV, JSON) or let Glue detect it automatically.
- Set a schedule or run it on-demand.
Step 2: Define Target and Transformation Logic
Once the source data is cataloged, define where the transformed data should go (e.g., another S3 bucket in Parquet format) and what transformations are needed (e.g., filtering, joining, type casting).
- In the Glue Console, go to “Jobs” and click “Create job”.
- Select the source and target tables from the Data Catalog.
- Choose a script generation option (Python or Scala).
- Customize the transformation logic in the editor if needed.
Step 3: Run and Monitor the Job
After configuration, run the job and monitor its progress through the AWS Console or CloudWatch.
- Check the job status in the “Jobs” section.
- View logs and error messages in CloudWatch Logs.
- Use job metrics to analyze execution time and DPU usage.
Pro Tip: Enable job bookmarks to ensure only new data is processed in incremental runs. Learn more about job bookmarks here.
Advanced Features of AWS Glue
Beyond basic ETL, AWS Glue offers advanced capabilities that empower data teams to build robust, scalable pipelines.
AWS Glue Studio: Visual ETL Development
Glue Studio provides a drag-and-drop interface for building ETL jobs without writing code. It’s ideal for users who prefer visual workflows over scripting.
- Create jobs by connecting data sources, transformations, and sinks visually.
- Preview data at each step of the transformation.
- Export jobs as scripts for version control or further customization.
Glue DataBrew: No-Code Data Preparation
AWS Glue DataBrew is a visual data preparation tool that allows users to clean and normalize data without writing code. It integrates directly with the Glue Data Catalog.
- Apply over 250 built-in transformations (e.g., remove duplicates, standardize dates).
- Use interactive profiling to understand data quality issues.
- Schedule recurring data preparation workflows.
Glue Elastic Views: Materialized Views Across Sources
Glue Elastic Views allows you to create materialized views that combine data from multiple sources (e.g., DynamoDB and RDS) into a single virtual table.
- Use SQL to define how data should be joined and aggregated.
- Automatically update views as source data changes.
- Query the view using Athena or Redshift without moving data.
Best Practices for Optimizing AWS Glue Performance
To get the most out of AWS Glue, follow these best practices for performance, cost, and reliability.
Partitioning and Compression Strategies
Efficient data layout significantly impacts job performance. Use partitioning and columnar formats like Parquet or ORC.
- Partition large datasets by date, region, or category.
- Compress data using Snappy or GZIP to reduce I/O and storage costs.
- Store data in columnar formats to improve query performance.
Using Job Bookmarks and Incremental Processing
Job bookmarks help track which data has already been processed, enabling incremental ETL and reducing processing time.
- Enable job bookmarks in the job settings.
- Handle schema changes gracefully with bookmark versions.
- Use them for CDC (Change Data Capture) scenarios.
Monitoring and Logging with CloudWatch
Effective monitoring ensures reliability and quick troubleshooting.
- Set up CloudWatch alarms for job failures or long runtimes.
- Use metrics like DPU utilization, shuffle spill, and garbage collection time.
- Enable logging in the job to capture custom debug messages.
Real-World Use Cases of AWS Glue
AWS Glue is used across industries to solve real business problems. Here are some practical applications.
Data Lake Integration
Organizations use AWS Glue to ingest, catalog, and transform data from various sources into a centralized data lake on Amazon S3.
- Ingest logs, IoT data, and transactional data into S3.
- Transform raw JSON/CSV into optimized Parquet format.
- Make data queryable via Athena or Redshift Spectrum.
Migration to Amazon Redshift
When migrating from on-premises databases to Amazon Redshift, AWS Glue automates schema conversion and data loading.
- Crawl source databases (e.g., Oracle, MySQL).
- Transform data to fit Redshift’s columnar structure.
- Load data using Redshift COPY commands via Glue jobs.
Real-Time Data Pipelines with Glue Streaming
AWS Glue supports streaming ETL from sources like Amazon Kinesis and MSK (Managed Streaming for Kafka).
- Process streaming data in near real-time.
- Apply transformations like filtering, enrichment, and aggregation.
- Output to S3, Redshift, or OpenSearch for downstream consumption.
“We reduced our ETL pipeline development time by 70% after switching to AWS Glue.” — Data Engineer, Financial Services Firm
Common Challenges and How to Solve Them
While AWS Glue is powerful, users may face certain challenges. Here’s how to overcome them.
Handling Schema Evolution
Data schemas often change over time (e.g., new columns, data type changes). AWS Glue provides mechanisms to handle this gracefully.
- Use schema versioning in the Data Catalog.
- Enable schema inference in crawlers to detect changes.
- Use Glue Schema Registry for enforcing schema compatibility (e.g., using Avro).
Dealing with Large-Scale Data Skew
Data skew can cause performance bottlenecks in Spark-based jobs. AWS Glue allows you to optimize partitioning and shuffling.
- Repartition data before expensive operations like joins.
- Use broadcast joins for small datasets.
- Enable dynamic frame optimization in Glue jobs.
Cost Management and DPU Optimization
Unoptimized jobs can lead to high DPU usage and costs.
- Start with the default number of DPUs and adjust based on job metrics.
- Use smaller DPUs for lightweight jobs.
- Terminate jobs early if they exceed expected runtime.
What is AWS Glue used for?
AWS Glue is used for automating ETL (Extract, Transform, Load) processes. It helps discover, catalog, transform, and move data between various data stores, making it ideal for building data lakes, migrating databases, and enabling analytics.
Is AWS Glue serverless?
Yes, AWS Glue is a fully serverless service. You don’t need to manage servers or clusters. It automatically provisions the necessary resources to run ETL jobs and scales them based on workload.
How much does AWS Glue cost?
AWS Glue pricing is based on Data Processing Units (DPUs). You pay per DPU-hour used. Additional costs may apply for the Data Catalog, Crawlers, and optional features like Glue DataBrew or Glue Elastic Views. Check the official pricing page for details.
Can AWS Glue handle streaming data?
Yes, AWS Glue supports streaming ETL jobs. You can process data from Amazon Kinesis or MSK (Managed Streaming for Kafka) in near real-time, enabling real-time analytics and event-driven architectures.
How does AWS Glue integrate with Athena?
AWS Glue integrates with Amazon Athena by providing the Data Catalog as a metadata repository. Athena uses the Glue Catalog to discover table schemas and run SQL queries directly on data stored in S3, eliminating the need for separate metadata management.
AWS Glue is a game-changer for modern data integration. From automated metadata discovery to serverless ETL and real-time streaming, it empowers organizations to build scalable, efficient data pipelines. By leveraging its advanced features and following best practices, teams can unlock the full potential of their data without the burden of infrastructure management. Whether you’re building a data lake, migrating to Redshift, or processing streams, AWS Glue provides the tools you need to succeed in the cloud era.
Recommended for you 👇
Further Reading: