Ever wondered what’s really happening behind the scenes of AWS? Dive into the ultimate guide on AWS status and uncover real-time insights, tools, and strategies to keep your cloud operations running smoothly.


Understanding AWS Status: What It Really Means

When we talk about aws status, we’re referring to the real-time health and operational performance of Amazon Web Services’ global infrastructure. This includes everything from compute instances and storage systems to networking and database services. AWS operates one of the most extensive cloud networks in the world, with data centers spread across multiple regions and availability zones. Monitoring the aws status is critical for businesses relying on AWS to ensure uptime, performance, and reliability.
Definition of AWS Status
The term aws status refers to the current operational condition of AWS services as reported by Amazon through its official status dashboard. This status reflects whether services are operating normally, experiencing degraded performance, undergoing maintenance, or facing outages. Each service—such as EC2, S3, Lambda, or RDS—is monitored individually, and their statuses are updated in near real-time.
- AWS status is publicly accessible via https://status.aws.com.
- Status updates are categorized by region and service.
- Incidents are logged with timestamps, descriptions, and resolution timelines.
“The AWS Status Dashboard is the single source of truth for service health.” — AWS Official Documentation
Why AWS Status Matters for Businesses
For enterprises and startups alike, downtime can mean lost revenue, damaged reputation, and frustrated users. According to a study by Gartner, the average cost of IT downtime is $5,600 per minute—making proactive monitoring of aws status a business imperative. Companies using AWS must stay informed about service disruptions that could impact customer-facing applications, internal workflows, or data pipelines.
- Financial institutions rely on AWS status to maintain compliance and transaction integrity.
- E-commerce platforms monitor aws status during peak sales events like Black Friday.
- DevOps teams use status alerts to trigger incident response protocols.
How AWS Defines Service Health
AWS categorizes service health into four primary states: Operational, Degraded Performance, Partial Degradation, and Service Disruption. These statuses are determined through automated monitoring systems and human verification. Each incident is assigned a severity level and tracked until resolution.
- Operational: All systems functioning normally.
- Investigating: AWS is aware of a potential issue and gathering data.
- Impaired: Some functionality is limited or slow.
- Resolved: The incident has been fixed and services restored.
These statuses are updated dynamically, and AWS provides detailed incident reports including root cause analysis (RCA) post-resolution.
How to Access the AWS Status Dashboard
The AWS Status Dashboard is the primary tool for monitoring the health of AWS services. It’s designed to be user-friendly, transparent, and accessible to both technical and non-technical stakeholders. Whether you’re a developer, system administrator, or CTO, knowing how to navigate this dashboard is essential.
Navigating the Official AWS Status Page
The official AWS status page at https://status.aws.com provides a comprehensive view of all AWS services across all regions. The interface is clean and organized, allowing users to quickly identify any ongoing issues.
- Services are listed alphabetically with color-coded indicators (green = healthy, yellow = degraded, red = disrupted).
- Regions are grouped by geographic location (e.g., US East, EU West, Asia Pacific).
- Each service entry includes a timeline of recent incidents.
Users can click on any service or region to view detailed incident reports, including start time, impact description, and current status updates.
Customizing Your Dashboard View
While the default view shows all services, users can customize their experience by subscribing to specific services or regions. This is particularly useful for organizations that only use a subset of AWS offerings.
- Use the “Subscribe” button to get email or RSS alerts.
- Filter by region to focus on your operational footprint.
- Bookmark specific service pages for quick access.
For example, if your application runs on EC2 in the US-West-2 region, you can set up alerts specifically for that combination, reducing noise from unrelated incidents.
Using RSS Feeds and Email Alerts
AWS allows users to subscribe to RSS feeds for real-time updates. This is a lightweight way to integrate aws status monitoring into existing workflows.
- RSS feeds are available for each service and region.
- Email subscriptions can be managed through the AWS Personal Health Dashboard.
- Third-party tools like Zapier can automate alerting based on RSS input.
These features empower teams to stay ahead of disruptions without constantly checking the dashboard manually.
The Role of AWS Service Health Dashboard vs. Personal Health Dashboard
It’s important to distinguish between the AWS Service Health Dashboard and the AWS Personal Health Dashboard. While both provide insights into service status, they serve different purposes and audiences.
Public vs. Account-Specific Monitoring
The AWS Service Health Dashboard (the public one at status.aws.com) provides a global view of all AWS services. It tells you if S3 is down in Europe or if Lambda is experiencing latency in Asia. However, it doesn’t tell you how these issues affect your specific resources.
In contrast, the AWS Personal Health Dashboard is integrated into the AWS Management Console and offers personalized alerts based on your account’s usage. It detects events that may impact your workloads, such as scheduled maintenance on an EC2 host or degraded performance in your RDS instance.
- Service Health Dashboard = Global, public, service-level view.
- Personal Health Dashboard = Private, account-specific, resource-level view.
“The Personal Health Dashboard is like a personal doctor for your AWS environment.” — AWS Blog
Key Features of the Personal Health Dashboard
The Personal Health Dashboard goes beyond simple status reporting. It offers intelligent insights, recommended actions, and integration with AWS CloudWatch and AWS Systems Manager.
- Proactive event detection before outages occur.
- Guided remediation steps for common issues.
- Integration with AWS Config for compliance tracking.
- API access for automation and custom tooling.
For example, if AWS plans to retire a physical host running your EC2 instance, the Personal Health Dashboard will notify you in advance and guide you through migrating to a new host.
When to Use Each Dashboard
Understanding when to use each dashboard can save time and improve incident response.
- Use the Service Health Dashboard when troubleshooting application issues and checking if AWS-wide outages are the cause.
- Use the Personal Health Dashboard for proactive maintenance, cost optimization, and account-specific diagnostics.
- Combine both for a complete picture of your cloud health.
Many enterprises use both dashboards in tandem, feeding data into internal monitoring systems for centralized visibility.
Common AWS Status Incidents and Their Impact
Despite AWS’s robust infrastructure, service disruptions do occur. Understanding common types of incidents helps organizations prepare and respond effectively. Historical data shows recurring patterns in aws status alerts, often tied to specific services or regions.
Major Outages in AWS History
Some of the most notable AWS outages have had widespread effects. For example:
- February 2017 S3 Outage: A typo during a debugging session in the US-EAST-1 region caused S3 to go offline for nearly four hours, affecting thousands of websites and services.
- December 2021 US-EAST-1 Outage: A network configuration issue disrupted services like Amazon.com, Netflix, and Slack.
- 2023 Lambda Throttling Incident: Increased error rates in Lambda functions impacted serverless applications globally.
These incidents highlight the cascading effect of regional failures in highly interconnected cloud environments.
Types of AWS Status Alerts
AWS categorizes incidents into several types based on cause and impact:
- Planned Maintenance: Scheduled updates that may require instance reboots.
- Network Issues: Connectivity problems between availability zones.
- Service Degradation: Slower response times or increased error rates.
- Capacity Constraints: Inability to launch new instances due to resource limits.
Each type requires a different response strategy, from simple monitoring to immediate failover procedures.
Real-World Business Impact of AWS Downtime
The financial and reputational cost of AWS downtime can be staggering. A 2022 report byuptime.com found that the average AWS outage lasts 90 minutes and costs companies over $500,000 in lost revenue.
- Streaming platforms lose viewership during live events.
- SaaS companies face SLA penalties and customer churn.
- E-commerce sites miss critical sales windows.
One retail company reported a $10 million loss during a single holiday season outage linked to RDS performance degradation.
Tools and APIs to Monitor AWS Status Automatically
Manual monitoring isn’t scalable. Organizations need automated tools to track aws status and trigger responses before users are affected. Fortunately, AWS and third parties offer powerful solutions.
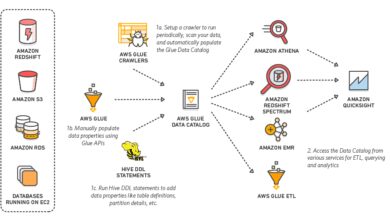
AWS Health API and CloudWatch Integration
The AWS Health API allows developers to programmatically access service health information. When combined with Amazon CloudWatch, it enables real-time alerting and automated remediation.
- Pull health events using the
DescribeEventsAPI call. - Create CloudWatch alarms based on health event severity.
- Trigger Lambda functions to auto-scale or reroute traffic during outages.
Example: A CloudWatch rule detects an RDS maintenance event and automatically shifts read traffic to a replica instance.
Third-Party Monitoring Tools
Many organizations use third-party tools to enhance their aws status monitoring capabilities.
- Datadog: Offers AWS health integration with customizable dashboards.
- PagerDuty: Routes AWS status alerts to on-call teams via SMS, phone, or email.
- Opsgenie: Provides incident management workflows tied to AWS health events.
- UptimeRobot: Monitors public AWS status pages and sends alerts.
These tools often provide better visualization, alerting logic, and integration with IT service management (ITSM) platforms.
Building Custom Status Alert Systems
For advanced users, building a custom monitoring system offers maximum control.
- Use AWS SNS to receive health notifications.
- Process messages with Lambda and store them in DynamoDB for auditing.
- Send alerts to Slack or Microsoft Teams using webhooks.
- Generate weekly reports on service health trends.
One fintech startup built a dashboard that correlates AWS status with internal application metrics, enabling faster root cause analysis.
Best Practices for Responding to AWS Status Alerts
Knowing the status is only half the battle. How you respond determines your resilience. Establishing best practices ensures your team can act quickly and effectively when aws status changes.
Creating an Incident Response Plan
Every organization using AWS should have a documented incident response plan that includes procedures for handling service disruptions.
- Define roles: Who monitors the dashboard? Who communicates with stakeholders?
- Establish escalation paths for critical incidents.
- Document failover procedures for key services.
Regularly test this plan through simulated outage drills.
Communicating with Stakeholders During Outages
Transparency builds trust. During an AWS-related outage, keep internal teams and customers informed.
- Use status pages like Statuspage.io to communicate updates.
- Avoid technical jargon in customer-facing messages.
- Provide estimated resolution times when available.
One SaaS company reduced customer support tickets by 60% simply by posting timely updates during an RDS outage.
Leveraging Multi-Region and Multi-AZ Architectures
The best defense against AWS status issues is a resilient architecture.
- Deploy applications across multiple availability zones (AZs).
- Use Route 53 for DNS failover between regions.
- Replicate critical data using S3 Cross-Region Replication.
During the 2021 US-EAST-1 outage, companies with multi-region setups were able to reroute traffic and maintain service.
Future of AWS Status Monitoring: Trends and Innovations
As cloud environments grow more complex, AWS continues to innovate in status monitoring and service health transparency. The future promises more predictive analytics, AI-driven insights, and deeper integration with DevOps workflows.
Predictive Maintenance and AI Alerts
AWS is investing in machine learning models that predict hardware failures and network congestion before they impact services.
- The Personal Health Dashboard already uses predictive analytics for host retirement notices.
- Future versions may predict S3 latency spikes or Lambda timeout risks.
- AI could recommend preemptive scaling or configuration changes.
This shift from reactive to proactive monitoring will redefine how teams interact with aws status.
Enhanced Transparency and Post-Mortem Reporting
After major incidents, AWS publishes detailed post-mortem reports. These are becoming more comprehensive, including timelines, root causes, and corrective actions.
- Reports are now available within 72 hours of incident resolution.
- They include metrics like MTTR (Mean Time to Repair) and impact scope.
- Customers can submit feedback on incident handling.
Increased transparency helps build trust and allows customers to improve their own architectures.
Integration with DevOps and CI/CD Pipelines
Future tools will embed aws status checks directly into development workflows.
- CI/CD pipelines could pause deployments during active AWS outages.
- Terraform or CloudFormation scripts might validate service health before applying changes.
- GitOps platforms could auto-rollback if a deployment coincides with a service disruption.
This level of integration ensures that infrastructure changes don’t compound existing issues.
What is the AWS Status Dashboard?
The AWS Status Dashboard is a public website that displays the real-time operational status of all AWS services across all regions. It helps users determine if service issues are due to AWS infrastructure problems or their own configurations.
How often is AWS status updated?
AWS status is updated in near real-time, typically within minutes of an incident being detected. The dashboard reflects changes as soon as AWS engineers confirm the issue and begin investigation.
Can I get automated alerts for AWS status changes?
Yes, you can subscribe to RSS feeds, use the AWS Personal Health Dashboard for account-specific alerts, or integrate with third-party tools like Datadog and PagerDuty for automated notifications via email, SMS, or chat platforms.
What should I do if my service is down and AWS status shows no issues?
If AWS status shows all systems operational but your service is down, the issue likely lies in your configuration, application code, or network setup. Check CloudWatch logs, VPC flow logs, and security groups for misconfigurations.
Does AWS provide compensation for service outages?
Yes, AWS offers Service Credits under its Service Level Agreement (SLA) if a service falls below the promised uptime (e.g., 99.9% for EC2). Customers can file a claim if they experience downtime that qualifies under the SLA terms.
Monitoring aws status is not just a technical task—it’s a business-critical function. From understanding the basics of the AWS Status Dashboard to building resilient architectures and leveraging automation, staying informed about service health ensures your applications remain available and performant. As AWS continues to evolve, so too will the tools and strategies for monitoring its status. By adopting best practices today, you position your organization to thrive in an increasingly cloud-dependent world.
Recommended for you 👇
Further Reading: